 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathNavigate: A Training-Free Pathology Agent with Surprise-Guided Scan and Shared Slide Memory for Whole-Slide Image VQA
May 22, 2026Whole-slide image visual question answering (WSI-VQA) frames pathology as an extreme-context search problem: to answer a free-form clinical query, a system must first navigate a gigapixel slide under a strict inspection budget to locate sparse, high-resolution evidence. Existing approaches largely fall into two paradigms: i) supervised pathology multimodal large language models (MLLMs) and agents can absorb localization and reasoning into learned modules, but they often couple navigation to task-specific supervision and retraining, limiting their practicality; ii) training-free pathology agents avoid this cost by keeping core models frozen, but often follow a question-first design, constructing the initial candidate set mainly from query-conditioned relevance. This can miss decisive morphology that is not named in the question, and force heavier inference-time scaffolding. To address this challenge, we introduce PathNavigate, a training-free pathology agent built around a scan-search-readout routine. Before question matching, PathNavigate scans the current slide at low magnification with a shared online memory module over frozen pathology features, producing a slide-specific surprise field that marks an abnormal-region pool. It then applies question-conditioned PLIP relevance only within this pool to select high-magnification search targets. Finally, it extracts local high-magnification evidence and answers with a frozen perceptor-adjudicator stack, using the same online memory as slide-level context. Experiments on WSI-VQA and SlideBench-BCNB show that the proposed scan-search-readout design improves answer accuracy and yields more interpretable evidence-selection trajectories with higher efficiency.The code is available online.
Thinking in Scales: Accelerating Gigapixel Pathology Image Analysis via Adaptive Continuous Reasoning
May 19, 2026Traditional whole slide image (WSI) analysis methods typically rely on the multiple instance learning (MIL) paradigm, which extracts patch-level features at high magnification and aggregates them for slide-level prediction. However, such exhaustive patch-level processing is computationally expensive, severely limiting the efficiency and scalability of WSI analysis. To address this challenge, we propose PathCTM (a Pathology-oriented Continuous Thought Model) that enables token-efficient scale-space continuous reasoning for gigapixel WSIs. PathCTM formulates diagnostic inference as a dynamic sequential information pursuit. It progressively transitions from low-magnification global to high-magnification local inspection, and adaptively terminates inference when sufficient evidence is gathered to effectively bound decision uncertainty. Specifically, it uses conditional computation for dynamic scale switching with attention-guided region pruning, coupled with confidence-aware early stopping. Extensive experiments demonstrate that, compared with standard MIL-based methods, PathCTM reduces the number of required image patches by 95.95% and shortens inference time by approximately 95.62%, while maintaining AUC without degradation. Code is available at https://github.com/JSGe-AI/PathCTM.
Mitigating the ID-OOD Tradeoff in Open-Set Test-Time Adaptation
Apr 02, 2026Open-set test-time adaptation (OSTTA) addresses the challenge of adapting models to new environments where out-of-distribution (OOD) samples coexist with in-distribution (ID) samples affected by distribution shifts. In such settings, covariate shift-for example, changes in weather conditions such as snow-can alter ID samples, reducing model reliability. Consequently, models must not only correctly classify covariate-shifted ID (csID) samples but also effectively reject covariate-shifted OOD (csOOD) samples. Entropy minimization is a common strategy in test-time adaptation to maintain ID performance under distribution shifts, while entropy maximization is widely applied to enhance OOD detection. Several studies have sought to combine these objectives to tackle the challenges of OSTTA. However, the intrinsic conflict between entropy minimization and maximization inevitably leads to a trade-off between csID classification and csOOD detection. In this paper, we first analyze the limitations of entropy maximization in OSTTA and then introduce an angular loss to regulate feature norm magnitudes, along with a feature-norm loss to suppress csOOD logits, thereby improving OOD detection. These objectives form ROSETTA, a $\underline{r}$obust $\underline{o}$pen-$\underline{se}$t $\underline{t}$est-$\underline{t}$ime $\underline{a}$daptation. Our method achieves strong OOD detection while maintaining high ID classification performance on CIFAR-10-C, CIFAR-100-C, Tiny-ImageNet-C and ImageNet-C. Furthermore, experiments on the Cityscapes validate the method's effectiveness in real-world semantic segmentation, and results on the HAC dataset demonstrate its applicability across different open-set TTA setups.
ARGaze: Autoregressive Transformers for Online Egocentric Gaze Estimation
Feb 04, 2026Online egocentric gaze estimation predicts where a camera wearer is looking from first-person video using only past and current frames, a task essential for augmented reality and assistive technologies. Unlike third-person gaze estimation, this setting lacks explicit head or eye signals, requiring models to infer current visual attention from sparse, indirect cues such as hand-object interactions and salient scene content. We observe that gaze exhibits strong temporal continuity during goal-directed activities: knowing where a person looked recently provides a powerful prior for predicting where they look next. Inspired by vision-conditioned autoregressive decoding in vision-language models, we propose ARGaze, which reformulates gaze estimation as sequential prediction: at each timestep, a transformer decoder predicts current gaze by conditioning on (i) current visual features and (ii) a fixed-length Gaze Context Window of recent gaze target estimates. This design enforces causality and enables bounded-resource streaming inference. We achieve state-of-the-art performance across multiple egocentric benchmarks under online evaluation, with extensive ablations validating that autoregressive modeling with bounded gaze history is critical for robust prediction. We will release our source code and pre-trained models.
HAAF: Hierarchical Adaptation and Alignment of Foundation Models for Few-Shot Pathology Anomaly Detection
Jan 24, 2026Precision pathology relies on detecting fine-grained morphological abnormalities within specific Regions of Interest (ROIs), as these local, texture-rich cues - rather than global slide contexts - drive expert diagnostic reasoning. While Vision-Language (V-L) models promise data efficiency by leveraging semantic priors, adapting them faces a critical Granularity Mismatch, where generic representations fail to resolve such subtle defects. Current adaptation methods often treat modalities as independent streams, failing to ground semantic prompts in ROI-specific visual contexts. To bridge this gap, we propose the Hierarchical Adaptation and Alignment Framework (HAAF). At its core is a novel Cross-Level Scaled Alignment (CLSA) mechanism that enforces a sequential calibration order: visual features first inject context into text prompts to generate content-adaptive descriptors, which then spatially guide the visual encoder to spotlight anomalies. Additionally, a dual-branch inference strategy integrates semantic scores with geometric prototypes to ensure stability in few-shot settings. Experiments on four benchmarks show HAAF significantly outperforms state-of-the-art methods and effectively scales with domain-specific backbones (e.g., CONCH) in low-resource scenarios.
From Pixel to Mask: A Survey of Out-of-Distribution Segmentation
Aug 14, 2025Out-of-distribution (OoD) detection and segmentation have attracted growing attention as concerns about AI security rise. Conventional OoD detection methods identify the existence of OoD objects but lack spatial localization, limiting their usefulness in downstream tasks. OoD segmentation addresses this limitation by localizing anomalous objects at pixel-level granularity. This capability is crucial for safety-critical applications such as autonomous driving, where perception modules must not only detect but also precisely segment OoD objects, enabling targeted control actions and enhancing overall system robustness. In this survey, we group current OoD segmentation approaches into four categories: (i) test-time OoD segmentation, (ii) outlier exposure for supervised training, (iii) reconstruction-based methods, (iv) and approaches that leverage powerful models. We systematically review recent advances in OoD segmentation for autonomous-driving scenarios, identify emerging challenges, and discuss promising future research directions.
Interpretable Multimodal Learning for Tumor Protein-Metal Binding: Progress, Challenges, and Perspectives
Apr 04, 2025In cancer therapeutics, protein-metal binding mechanisms critically govern drug pharmacokinetics and targeting efficacy, thereby fundamentally shaping the rational design of anticancer metallodrugs. While conventional laboratory methods used to study such mechanisms are often costly, low throughput, and limited in capturing dynamic biological processes, machine learning (ML) has emerged as a promising alternative. Despite increasing efforts to develop protein-metal binding datasets and ML algorithms, the application of ML in tumor protein-metal binding remains limited. Key challenges include a shortage of high-quality, tumor-specific datasets, insufficient consideration of multiple data modalities, and the complexity of interpreting results due to the ''black box'' nature of complex ML models. This paper summarizes recent progress and ongoing challenges in using ML to predict tumor protein-metal binding, focusing on data, modeling, and interpretability. We present multimodal protein-metal binding datasets and outline strategies for acquiring, curating, and preprocessing them for training ML models. Moreover, we explore the complementary value provided by different data modalities and examine methods for their integration. We also review approaches for improving model interpretability to support more trustworthy decisions in cancer research. Finally, we offer our perspective on research opportunities and propose strategies to address the scarcity of tumor protein data and the limited number of predictive models for tumor protein-metal binding. We also highlight two promising directions for effective metal-based drug design: integrating protein-protein interaction data to provide structural insights into metal-binding events and predicting structural changes in tumor proteins after metal binding.
H2ST: Hierarchical Two-Sample Tests for Continual Out-of-Distribution Detection
Mar 19, 2025



Task Incremental Learning (TIL) is a specialized form of Continual Learning (CL) in which a model incrementally learns from non-stationary data streams. Existing TIL methodologies operate under the closed-world assumption, presuming that incoming data remains in-distribution (ID). However, in an open-world setting, incoming samples may originate from out-of-distribution (OOD) sources, with their task identities inherently unknown. Continually detecting OOD samples presents several challenges for current OOD detection methods: reliance on model outputs leads to excessive dependence on model performance, selecting suitable thresholds is difficult, hindering real-world deployment, and binary ID/OOD classification fails to provide task-level identification. To address these issues, we propose a novel continual OOD detection method called the Hierarchical Two-sample Tests (H2ST). H2ST eliminates the need for threshold selection through hypothesis testing and utilizes feature maps to better exploit model capabilities without excessive dependence on model performance. The proposed hierarchical architecture enables task-level detection with superior performance and lower overhead compared to non-hierarchical classifier two-sample tests. Extensive experiments and analysis validate the effectiveness of H2ST in open-world TIL scenarios and its superiority to the existing methods. Code is available at \href{https://github.com/YuhangLiuu/H2ST}{https://github.com/YuhangLiuu/H2ST}.
LLM-PQA: LLM-enhanced Prediction Query Answering
Sep 02, 2024



The advent of Large Language Models (LLMs) provides an opportunity to change the way queries are processed, moving beyond the constraints of conventional SQL-based database systems. However, using an LLM to answer a prediction query is still challenging, since an external ML model has to be employed and inference has to be performed in order to provide an answer. This paper introduces LLM-PQA, a novel tool that addresses prediction queries formulated in natural language. LLM-PQA is the first to combine the capabilities of LLMs and retrieval-augmented mechanism for the needs of prediction queries by integrating data lakes and model zoos. This integration provides users with access to a vast spectrum of heterogeneous data and diverse ML models, facilitating dynamic prediction query answering. In addition, LLM-PQA can dynamically train models on demand, based on specific query requirements, ensuring reliable and relevant results even when no pre-trained model in a model zoo, available for the task.
Segment Every Out-of-Distribution Object
Nov 27, 2023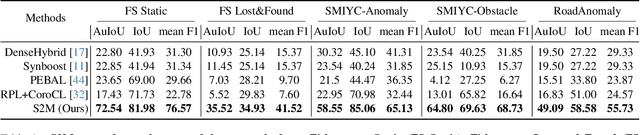

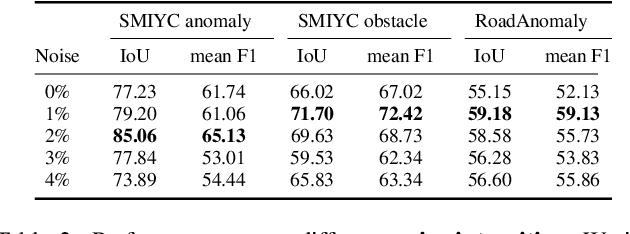
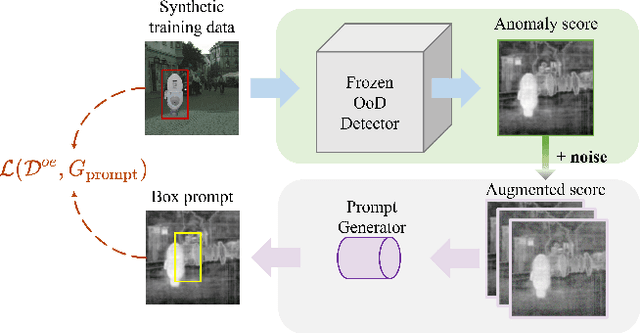
Semantic segmentation models, while effective for in-distribution categories, face challenges in real-world deployment due to encountering out-of-distribution (OoD) objects. Detecting these OoD objects is crucial for safety-critical applications. Existing methods rely on anomaly scores, but choosing a suitable threshold for generating masks presents difficulties and can lead to fragmentation and inaccuracy. This paper introduces a method to convert anomaly Score To segmentation Mask, called S2M, a simple and effective framework for OoD detection in semantic segmentation. Unlike assigning anomaly scores to pixels, S2M directly segments the entire OoD object. By transforming anomaly scores into prompts for a promptable segmentation model, S2M eliminates the need for threshold selection. Extensive experiments demonstrate that S2M outperforms the state-of-the-art by approximately 10\% in IoU and 30\% in mean F1 score, on average, across various benchmarks including Fishyscapes, Segment-Me-If-You-Can, and RoadAnomaly datasets.